Fast Monocular Scene Reconstruction with Global-Sparse Local-Dense Grids
Wei Dong, Chris Choy, Charles Loop, Yuke Zhu, Or Litany, Anima Anandkumar
CVPR 2023
TL;DR
We combine classical TSDF fusion and differentiable volume rendering to reconstruct scenes from monocular images. Without an MLP, it is fast, and the results are comparable to SOTA.
Abstract
Indoor scene reconstruction from monocular images has long been sought after by augmented reality and robotics developers. Recent advances in neural field representations and monocular priors have led to remarkable results in scene-level surface reconstructions. The reliance on Multilayer Perceptrons (MLP), however, significantly limits speed in training and rendering.
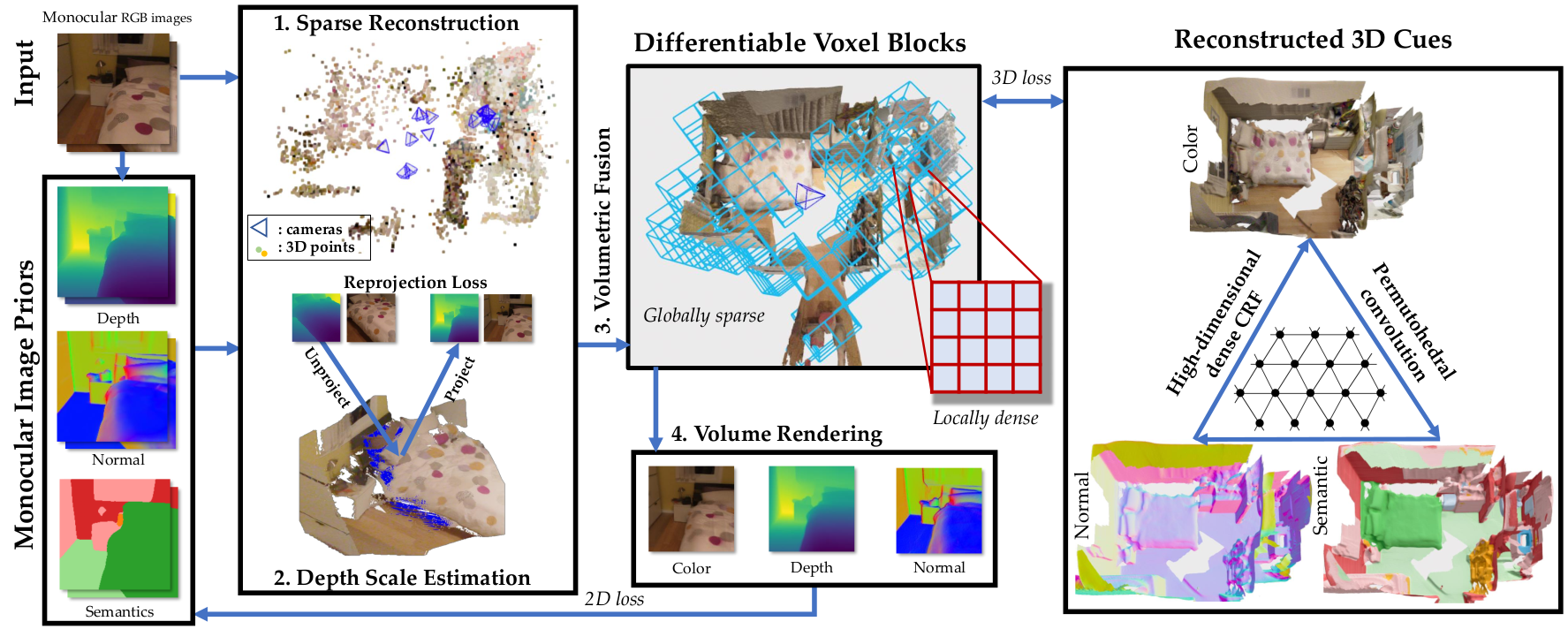
In this work, we propose to directly use signed distance function (SDF) in sparse voxel block grids for fast and accurate scene reconstruction without MLPs. Our globally sparse and locally dense data structure exploits surfaces’ spatial sparsity, enables cache-friendly queries, and allows direct extensions to multi-modal data such as color and semantic labels.
To apply this representation to monocular scene reconstruction, we develop a scale optimization algorithm for fast geometric initialization from monocular depth priors. We apply differentiable volume rendering from this initialization to refine details with fast convergence. We also introduce efficient high-dimensional Continuous Random Fields (CRFs) to further exploit the semantic-geometry consistency between scene objects.
Experiments show that our approach is 10x faster in training and 100x faster in rendering while achieving comparable accuracy to state-of-the-art neural implicit methods.
Workflow
- First generate dense depth priors via omnidata, a variation of DPT. These priors are not scale-consistent.
- Then run sparse structure from motion via COLMAP. It generates sparse but scale-consistent points.
- Use sparse points to optimize consistent dense depth scales.
- Apply classical volumetric TSDF-fusion and filtering to obtain initial reconstruction.
- Use differentiable volume rendering to refine details, with optional further CRF regularization.
Code
- The scale preprocessing part are hosted in mini-omnidata.
- The core data structures and optimizers are hosted in torch-ash, coming soon.
Video Supplement
Selected Results



Concurrent works
Citation
@article{dong2023fast,
title={Fast Monocular Scene Reconstruction with Global-Sparse Local-Dense Grids},
author={Dong, Wei and Choy, Chris and Loop, Charles, and Zhu, Yuke, and Litany, Or and Anandkumar, Anima},
journal={CVPR},
year={2023}
}